The Problem
In a traditional inverted index, we see a mapping from keywords to documents which enables searching a corpus be it the web, email, or a research database. Oftentimes, particularly while using a web search engine, users are not looking for a webpage - they are looking for information inside the webpages. This means that question answering is a very important topic in information retrieval, and is beginning to spawn new technologies like Google’s Knowledge Graph.
An important subset of question answering is when users desire entities as search results. Generally speaking an entity is a noun, and some of the most common entity classes are “person”, “location”, and “organization”. The concept of entities as search results or as search inputs, an “entity search,” is not easily supported by a traditional inverted index from keywords to documents. Using such an inverted index would require scanning result document contents and aggregating at search time, which is roundabout and expensive.
A far more natural implementation of an entity search would be an inverted index which can map from both terms and entities, to both documents and entities. This approach requires that Named Entity Recognition (NER), and some level of aggregation, be completed at indexing time. While this makes query time more efficient, it poses some challenges.
Named Entity Recognition
One challenge of building an entity-aware system is the task of Named Entity Recognition (NER). NER has been well studied, and there are a number of open source implementations using a variety of approaches. There are broadly three categories of NER: probabilistic, gazetteer, and rule-based.
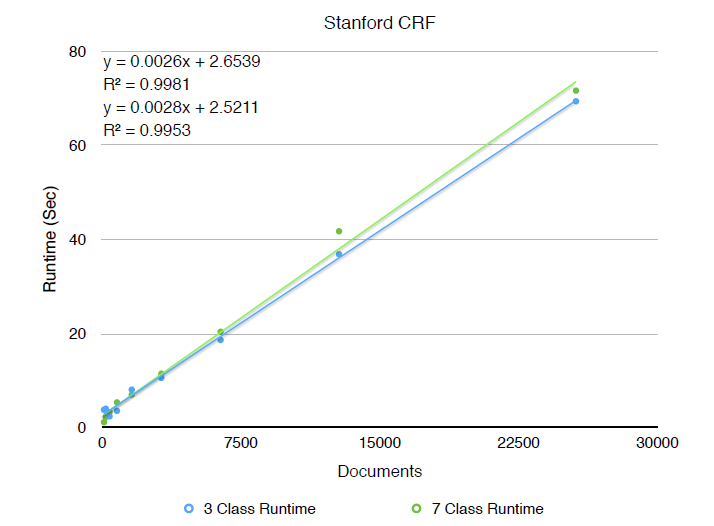
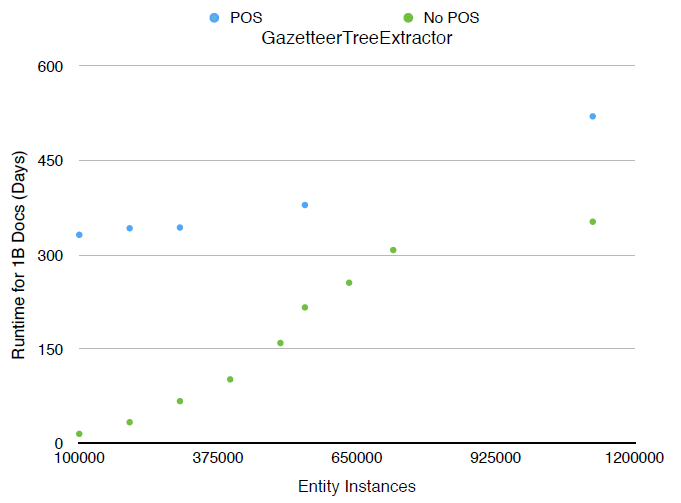
Probabilistic approaches rely on machine learning techniques to identify features in text which signal the existence of an entity. This often goes hand in hand with Part of Speech (POS) tagging, which is also a well studied problem. Using a probabilistic approach to NER requires a model is trained on an annotated training set, which can be tedious to produce.
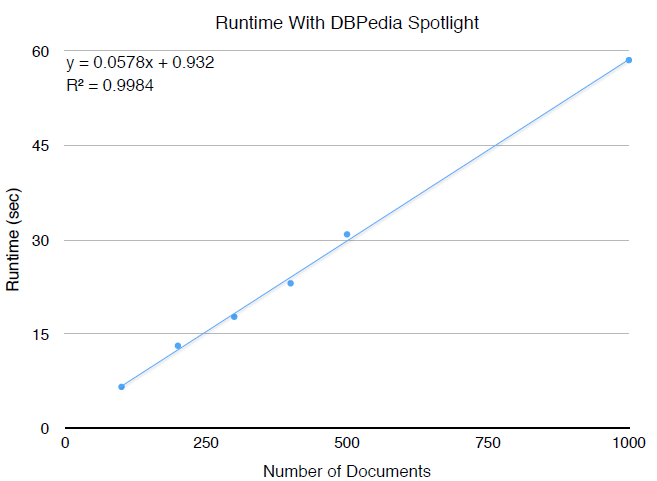
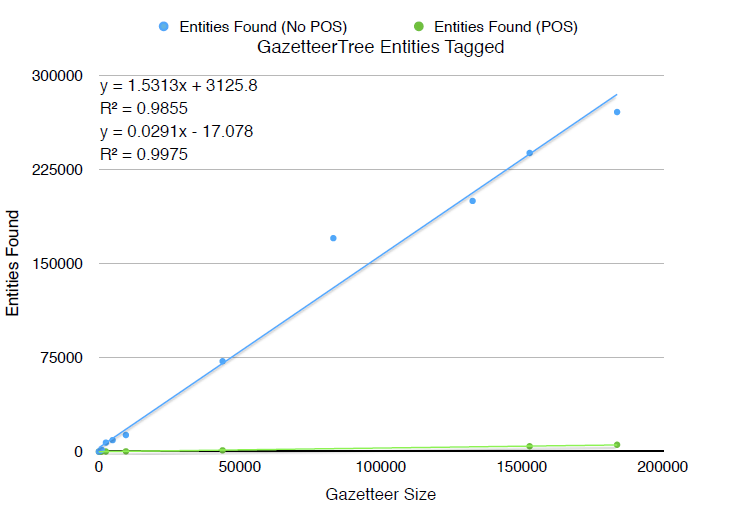
Gazetteer approaches rely on a dictionary of known entities and some form of string matching to identify where any of these entities exist in text. Exact string matching tends to produce low recall in most scenarios, so there exist a number of approximate string matching techniques in the literature for gazetteer NER. Though gazetteer NER can be quite powerful, a complete and accurate dictionary of known entities can be difficult to produce.
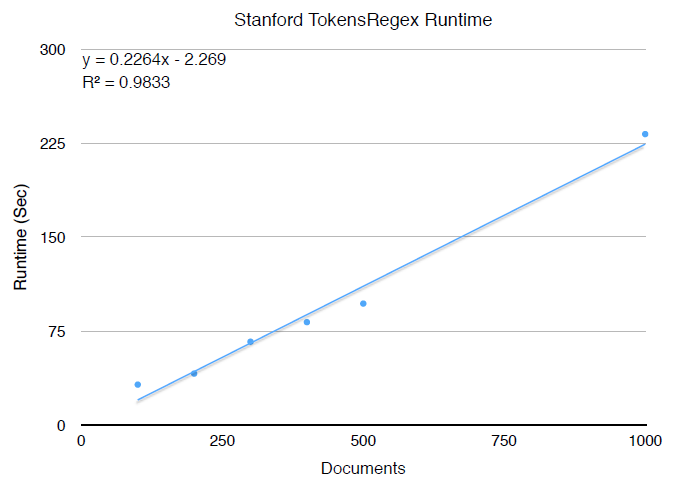
Rule-based approaches are quite similar to probabilistic approaches in that they rely on contextual features to identify entities. The difference is that these features are not learned, they are specified by the user. Though this can work very well in some cases, it generally requires deep domain knowledge and can be prohibitively tedious.
There are hybrid systems in existence. Stanford’s Conditional Random Field NER classifier has the option of including a gazette during training of the probabilistic model. This gazette is used as additional features for training the model, and does not guarantee that an exact string match in the gazette will result in the associated entity tag. This is a very interesting concept, as it may help to mitigate the need for a complete gazette, though its required labeled training data may present an issue for a large number of entity types.
Generally, not one NER approach is sufficient for all cases. Domain and application specific NER configuration is a must for enabling entity search, and has thus been one focus of this research.
Index Design
Another challenge of building an entity aware system is the design of the index itself. There can be a number of ways to represent entities within the index, and each has benefits and drawbacks.
One approach would be to treat entity instances as documents. This is intuitive because entities are search targets. However, this requires a good deal of preprocessing since one entity instance can appear in a large number of documents. It may further complicate things when the index is updated with new documents, as all of the entity instances in the new document require changes be made to their corresponding entity documents. Additionally, there can be many ways to store the context of each entity instance in an entity document so that the entity can be searched; it is not unreasonable that these entity documents can become very large.
Another approach would be to simply tag entities within each document. This would allow for a lighter preprocessing phase, though more work is required at query time to convert document results into entity results.
Another approach would be to create a document for every appearance of an entity instance. While this trivializes the problem of updating the index with new documents, it requires aggregation be done at query time, which may be slow. Additionally, this can lead to a very large number of entity occurrence documents in the index.
A final approach is to leverage the information stored in the index for each term to document matching. If a term maps to a document, typically additional information such as frequency of that term in the document is recorded. Entity instances near a term in that document could be stored along with this information. This lessens the preprocessing requirements, but makes search quite unnatural to implement. It is also counterintuitive.
The goal for this summer was set to create a demo system which can build and search an entity aware inverted index, and is adaptable to a variety of corpuses and applications. As one of three undergraduates on the team, my specific focus was on enabling NER and the indexing process.